多模态集成
微语系统支持多模态能力,可以理解和处理用户上传的图片、视频和音频内容,并结合知识库给出精准回答。本文档将介绍微语系统的多模态功能及其应用场景。
概述
多模态集成是指系统能够处理文本、图像、视频、音频等多种形式的信息输入,并将其转化为统一的知识表示,从而实现跨模态的信息理解与响应。微语系统集成了先进的多模态模型,使客服机器人能够:
- 读取并理解用户上传的图片内容
- 提取视频中的关键信息和场景
- 转录并理解音频内容
- 结合企业知识库,对多模态内容进行专业解答
使用步骤
下面以智谱AI为例说明
导入/创建视觉模型
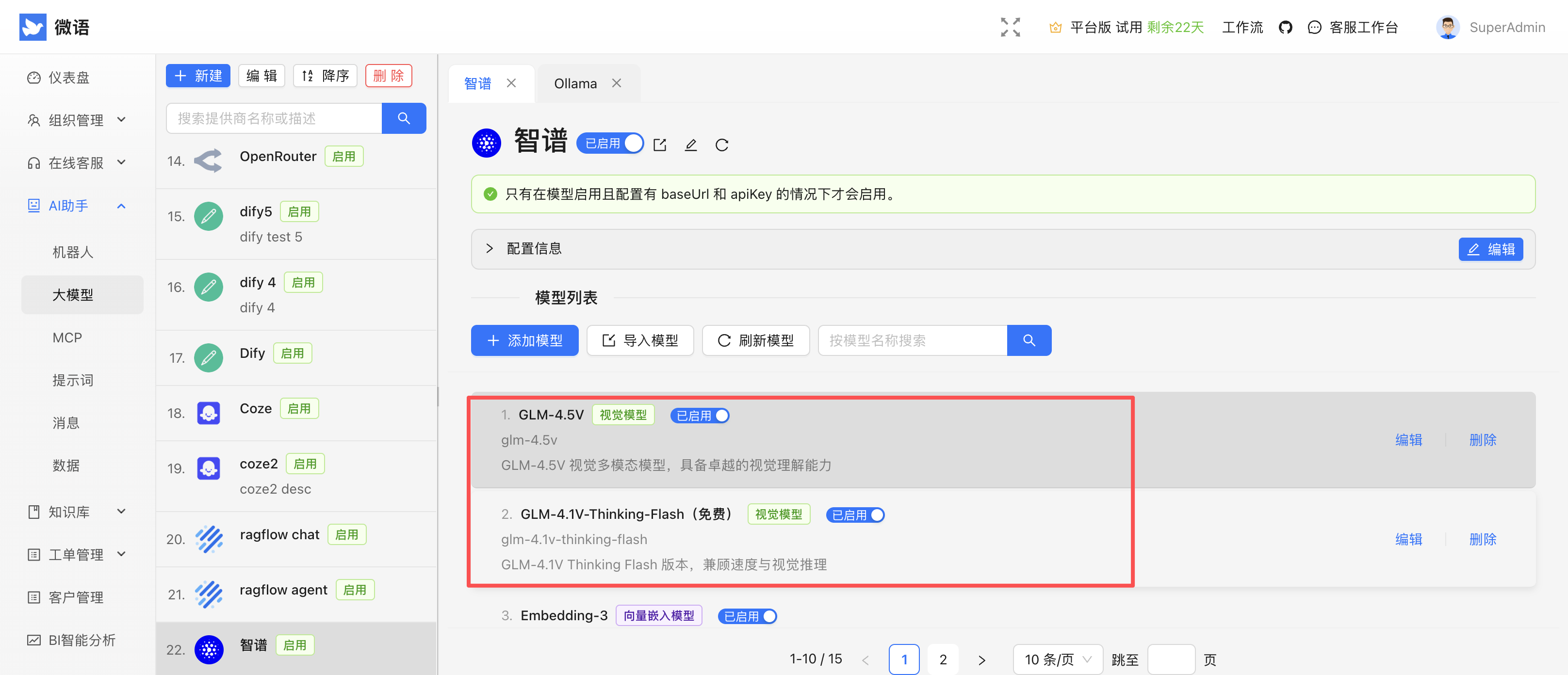
配置视觉模型
修改模型提供商
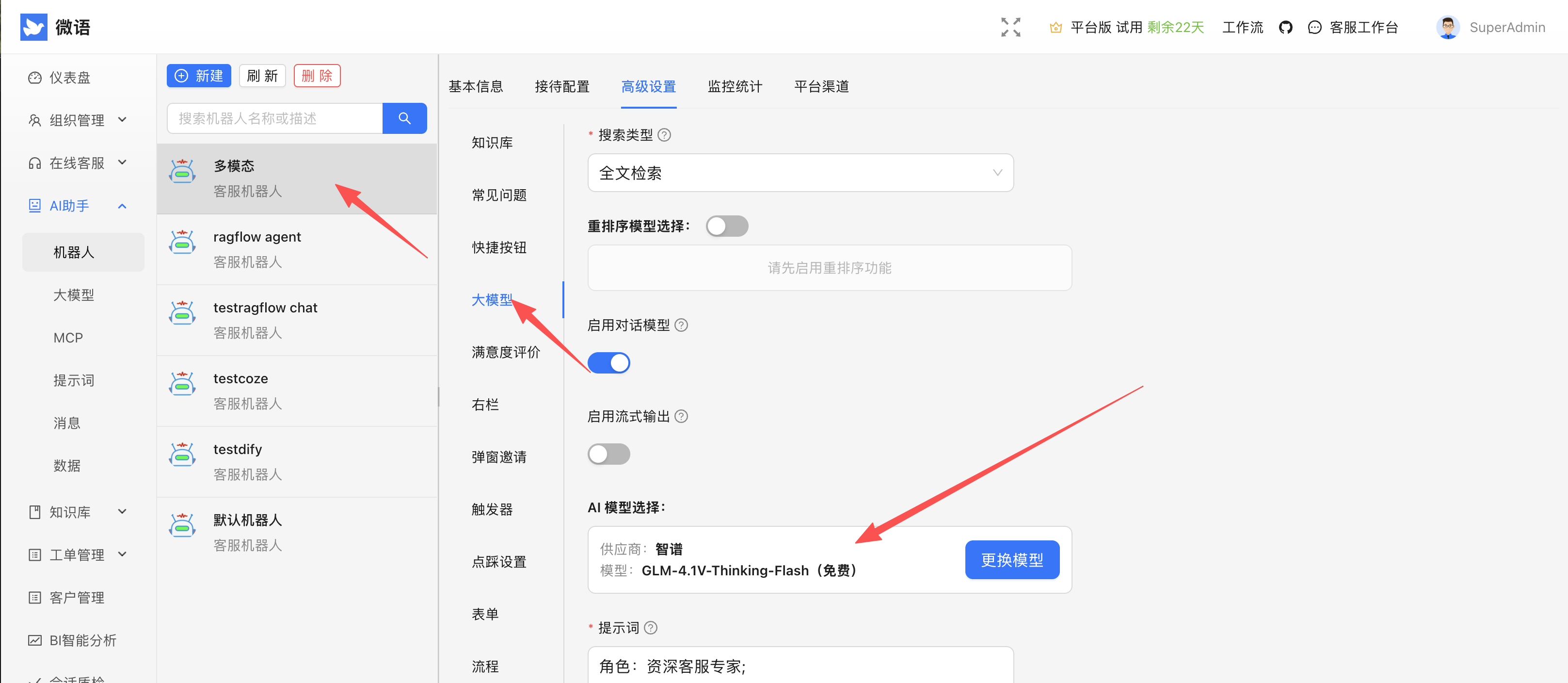
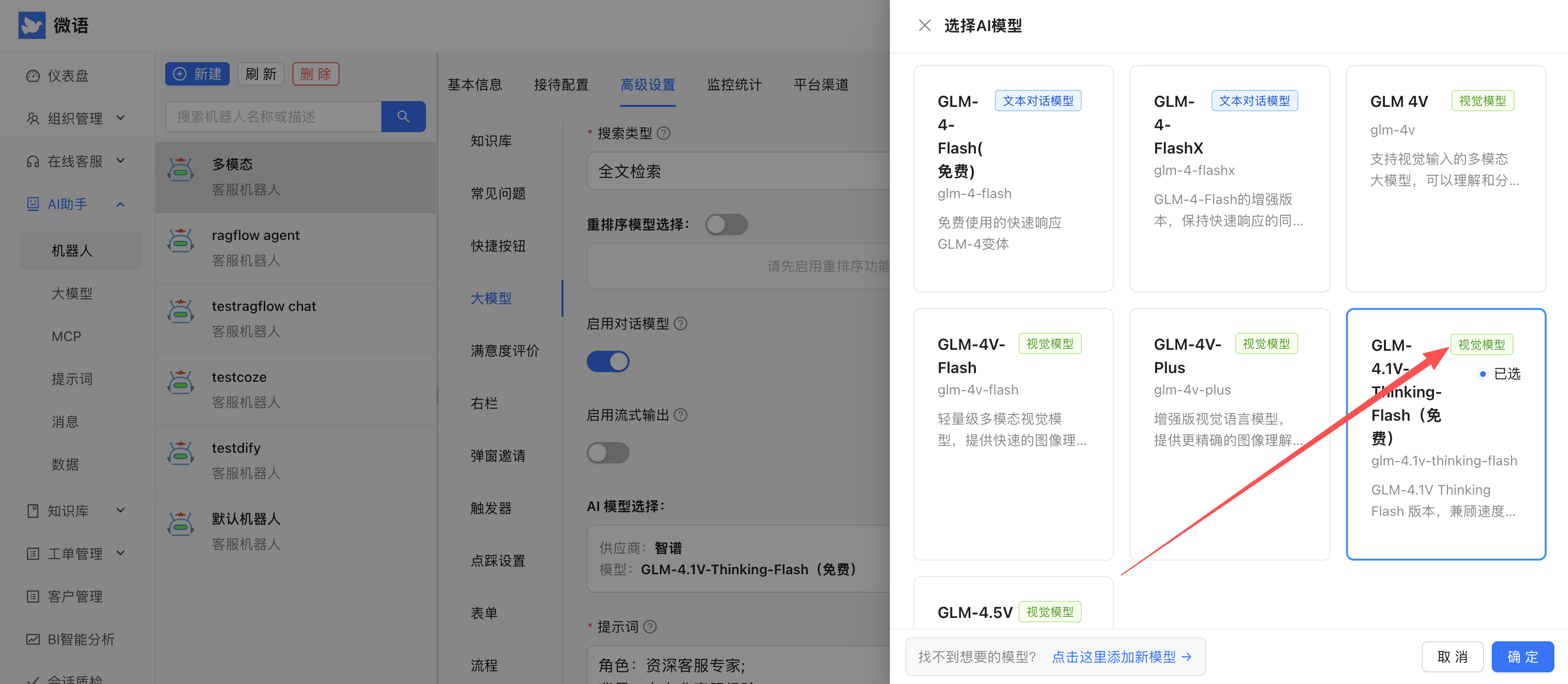
选择视觉模型
预览
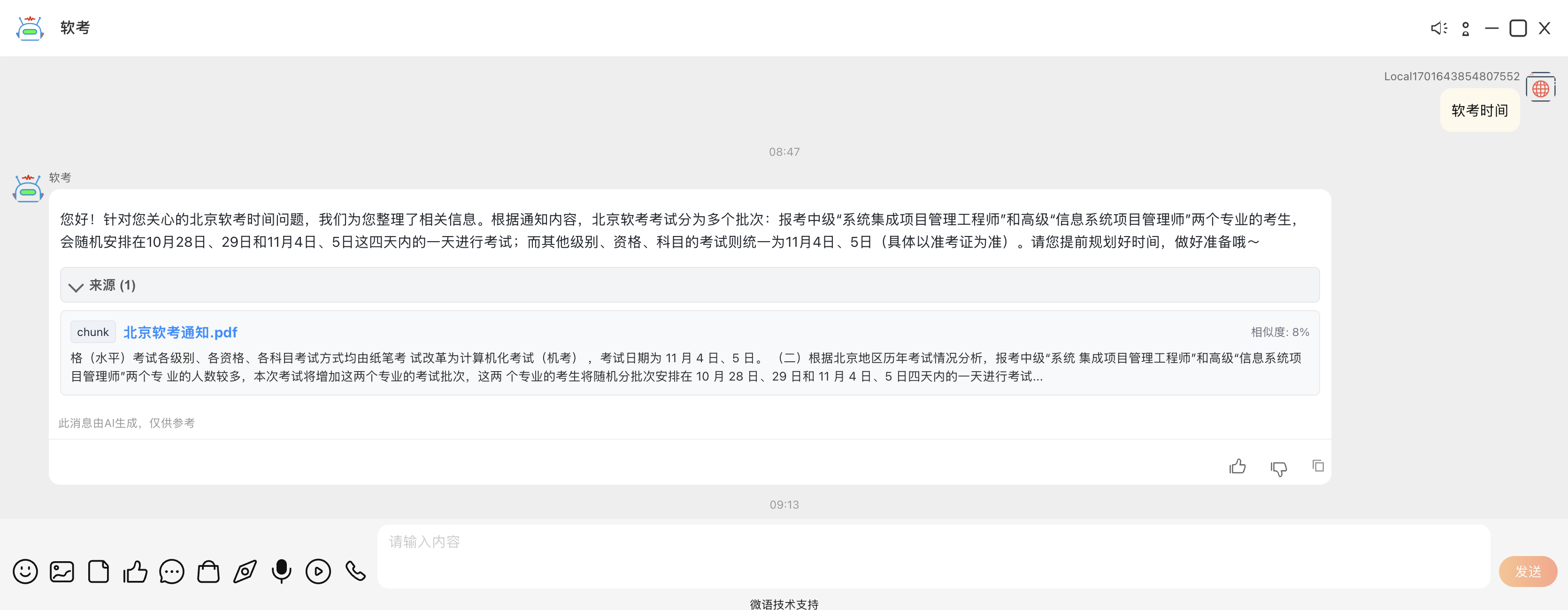
支持图片问答
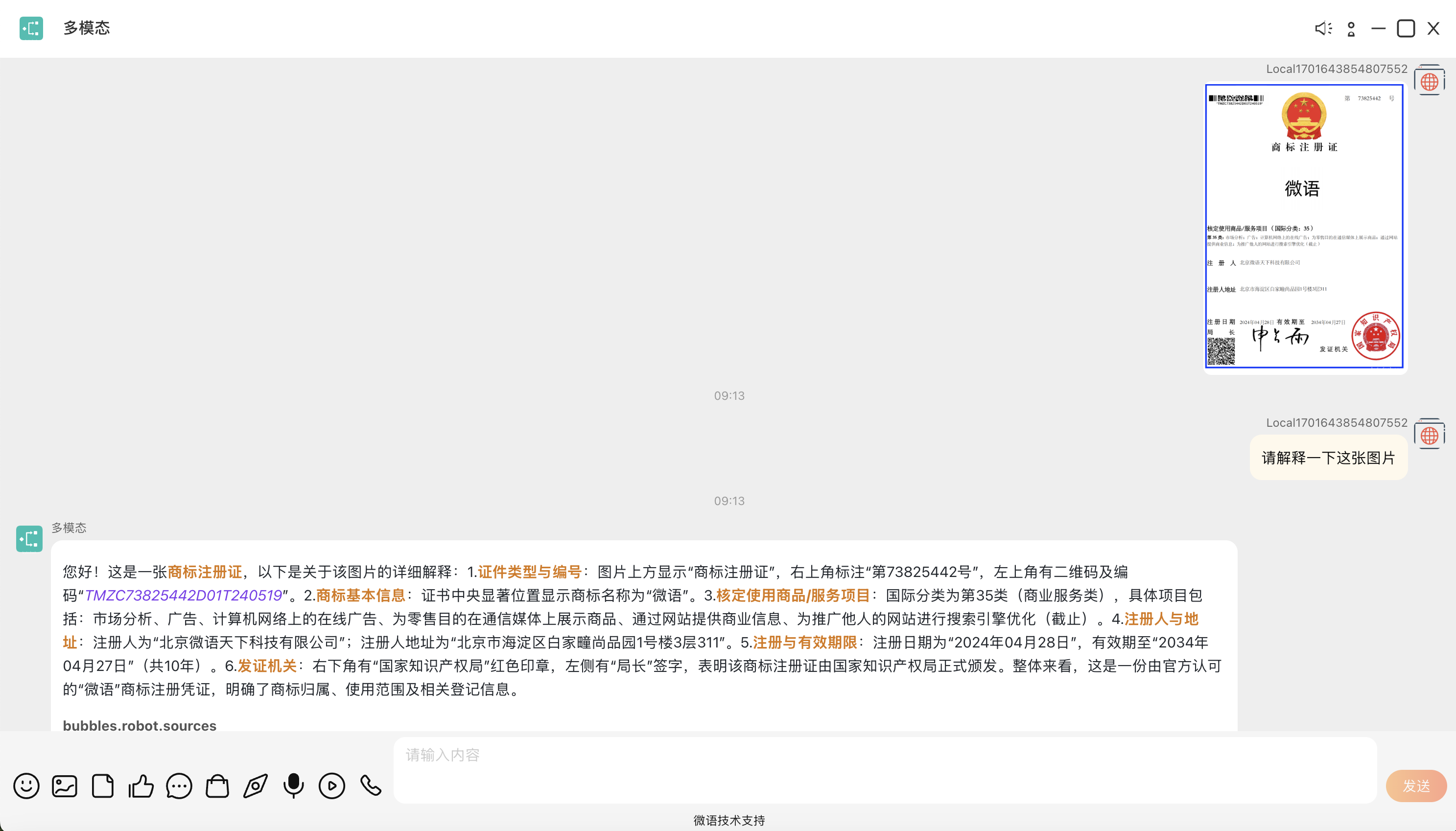
支持显示答案引用来源
总结
微语系统的多模态集成能力大大拓展了智能客服的服务边界,使系统能够处理更加丰富的用户输入形式,提供更加全面、精准的服务。通过结合企业知识库,微语系统不仅能够"看懂"和"听懂"用户问题,还能给出专业的解答,真正实现智能化的客户服务体验。