知识库-实现原理
介绍
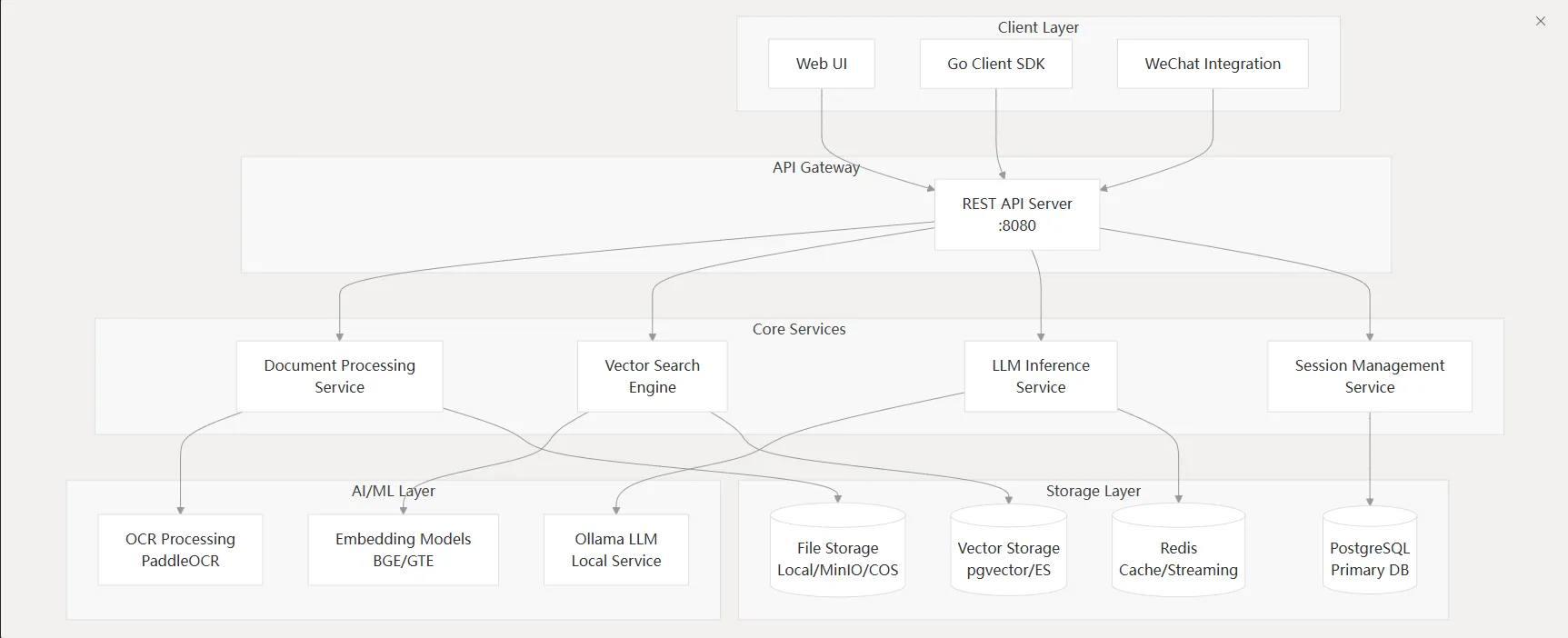
微语知识库是一个可立即在生产环境投入的企业级RAG(检索增强生成)知识库,实现智能文档理解和检索功能。该系统采用模块化设计,将文档理解、向量存储、推理文件等功能分离。
核心特性
- 模块化设计:文档解析、向量存储、检索推理等功能独立,便于扩展和维护
- 多模态支持:支持文本、图片、表格等多种内容类型的理解和检索
- 高性能架构:采用异步处理、并发优化等技术,支持大规模并发请求
Pipeline 处理流程
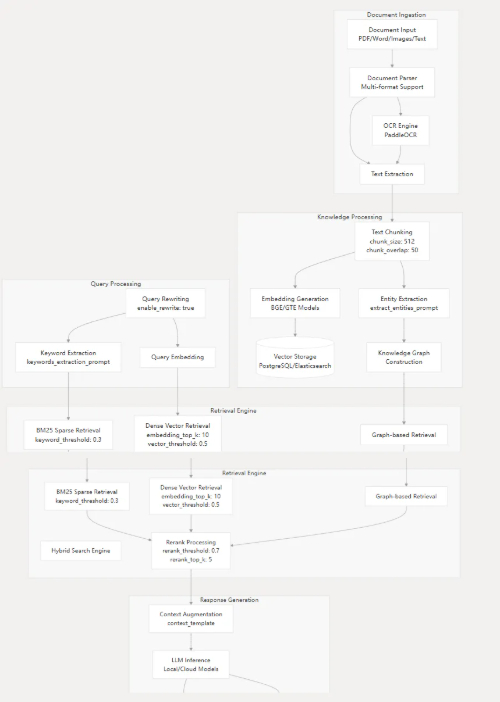
微语知识库处理文档需要多个步骤:插入 → 知识提取 → 索引 → 检索 → 生成,整个流程支持多种检索方法,确保信息检索的准确性和完整性。
完整数据流示例
以用户上传的一张住宿流水单PDF文件为例,详细介绍其数据流:
1. 接收请求与初始化
- 请求识别: 系统收到请求,分配唯一的
request_id=Lkq0OGLYu2fV,用于追踪整个处理流程 - 租户与会话验证:
- 验证租户信息(ID: 1, Name: Default Tenant)
- 处理知识库问答请求,归属会话
1f241340-ae75-40a5-8731-9a3a82e34fdd
- 用户问题: "入住的房型是什么"
- 消息创建: 为用户提问和AI回答分别创建消息记录
2. 知识库问答流程启动
系统启动完整处理管道,包含9个事件:
[rewrite_query, preprocess_query, chunk_search, chunk_rerank, chunk_merge, filter_top_k, into_chat_message, chat_completion_stream, stream_filter]
3. 事件执行详情
事件1: rewrite_query - 问题改写
- 目的: 结合上下文理解用户真实意图,提高检索精确度
- 操作:
- 检索当前会话最近20条历史消息作为上下文
- 调用
deepseek-r1:7b大语言模型 - 根据聊天历史分析,将问题改写得更具体
- 结果: "入住的房型是什么" → "Liwx本次入住的房型是什么"
事件2: preprocess_query - 问题预处理
- 目的: 将改写后的问题进行分词,转换为适合搜索引擎处理的关键词序列
- 结果: 生成关键词序列用于后续检索
事件3: chunk_search - 知识区块检索(核心步骤)
执行两次混合搜索策略:
第一次搜索(完整问句):
- 向量检索: 使用
bge-m3:latest模型将问句转换为1024维向量,在PostgreSQL中进行相似度搜索 - 关键词检索: 基于BM25算法的全文搜索
- 结果合并: 去重后得到相关知识区块
第二次搜索(关键词序列):
- 使用预处理后的关键词重复向量和关键词检索
- 与第一次搜索结果进行合并去重
双重搜索的优势:
- 语义检索的深度: 完整句子能更好利用向量模型的语义理解能力
- 关键词检索的广度: 确保包含核心关键词的内容不被遗漏
事件4: chunk_rerank - 结果重排序
- 目的: 使用专门的重排序模型对检索结果进行精确排序
- 支持的重排器类型:
- Normal Reranker: 基于BERT的交叉编码器,如
bge-reranker-v2-m3 - LLM-based Reranker: 基于大语言模型的重排,如
bge-reranker-v2-gemma - Layerwise Reranker: 利用LLM多层信息的重排,如
bge-reranker-v2-minicpm-layerwise
- Normal Reranker: 基于BERT的交叉编码器,如
事件5: chunk_merge - 区块合并
- 目的: 将内容相邻或相关的知识区块合并,形成更完整的上下文
- 策略: 基于相似度和位置关系进行智能合并
事件6: filter_top_k - Top-K过滤
- 目的: 保留最相关的K个结果,防止过多无关信息干扰
- 配置: 默认保留Top-5最相关区块
事件7-8: 答案生成
- into_chat_message: 将检索结果、用户问题、历史对话整合为完整提示
- chat_completion_stream: 调用大语言模型生成流式回答
Prompt组装策略:
关键约束:必须严格按照所提供文档回答,禁止使用模型自身知识
未知情况处理:文档信息不足时,回复"根据所掌握的资料,无法回答这个问题"
引用要求:引用文档内容时,在句末添加文档编号标识
事件9: stream_filter - 流式输出过滤
- 目的: 过滤模型输出中的特殊标记
- 处理: 移除
<think>、</think>等思考过程标记
4. 完成与响应
- 发送引用: 将参考的知识区块作为引用信息发送给前端
- 更新消息: 完整回答更新到消息记录
- 请求结束: 返回200状态码,完成RAG流程
文档解析切分
工作流程原理
第一阶段: 请求接收与分发
- gRPC服务启动: 根据环境变量配置启动多进程多线程服务器
- 请求处理: 接收文件信息和解析配置
- 解析器选择: 根据文件类型选择对应的具体解析器
第二阶段: 核心解析与分块
顺序保证机制:
- 统一文本流创建: 逐页处理文档,按页面顺序拼接内容
- 原子化保护: 使用正则表达式识别表格和图像为不可分割单元
- 顺序分块: 严格按照原始顺序将内容分割为适当大小的块
- 信息附加: 为每个块附加图像、表格等多模态信息
第三阶段: 多模态处理
并发处理策略:
- 并发任务启动: 使用asyncio并发处理所有文本块中的图片
- 图片持久化:
- 提取��图片引用
- 上传到对象存储(COS/MinIO)
- 生成持久化URL
- AI处理:
- OCR: 使用PaddleOCR识别图片中的文字
- 图像描述: 调用视觉语言模型生成图片描述
- 并发控制: 使用Semaphore限制并发数量
第四阶段: 结果返回
将处理完成的Chunk对象转换为gRPC Protobuf格式,返回给调用方。
性能和监控
监控体系
- 分布式跟踪: 集成Zipkin追踪请求在分布式系统中的完整执行路径
- 健康监控: 实时监控各服务组件的健康状态
- 性能指标: 监控检索延迟、并发处理能力、资源使用情况
可扩展性
- 水平扩展: 通过容器化部署支持多实例扩展
- 负载均衡: 支持请求负载均衡,满足大规模并发需求
- 资源优化: 智能资源调度,优化GPU/CPU使用效率
技术问答
Q1: 为什么要执行两次混合搜索?
目的: 最大化检索准确性和召回率,采用查询扩展和多策略检索组合。
两次搜索的差异:
- 第一次: 使用语法完整的自然语言问句,利用向量模型的语义理解能力
- 第二次: 使用分词后的关键词序列,确保关键词匹配不遗漏
优势: 结合语义检索的深度和关键词检索的广度,提高检索的准确性和完整性。
Q2: 重排序模型有哪些类型?
| 类型 | 模型基础 | 工作原理 | 适用场景 |
|---|---|---|---|
| Normal Reranker | 交叉编码器(BERT) | Query和Passage深度交互,输出相关性分数 | 生产环境首选,效果好易部署 |
| LLM-based Reranker | 因果语言模型(Gemma) | 转为Yes/No预测任务,用概率作分数 | 复杂推理场景,计算资源充足 |
| Layerwise Reranker | 因果语言模型(MiniCPM) | 从多个网络层提取相关性信号 | 追求SOTA性能的研究场景 |
Q3: 如何组装上下文发送给大模型?
提示词设计原则:
系统角色:你是一个基于文档的问答助手
关键约束:必须严格按照所提供文档回答,禁止使用自身知识
未知处理:文档信息不足时回复"根据所掌握的资料,无法回答这个问题"
引用要求:引用文档内容时在句末添加文档编号 [doc-1]
上下文组装结构:
- 系统指令和约束说明
- 检索到的相关文档内容(按相关性排序)
- 对话历史(必要时)
- 用户当前问题